
The internet has become an integral part of our daily lives, with billions of users logging on to access information, entertainment, and communication. URLs, or Uniform Resource Locators, are the foundation of the web and are the gateway to the vast array of content that the internet provides.
In this article, we will learn about URLs, their structure, history, their role in the world wide web, and much more.
What is a URL?
A URL, which stands for Uniform Resource Locator, is a reference to a web resource that specifies its location on a computer network and a mechanism for retrieving it. URLs are used for locating web pages, images, videos, and other files on the internet. It is like a street address for the internet and is used to navigate to a particular page.
For example, the URL of the Google home page is https://www.google.com/. When you type that URL into the address bar of your browser, the browser will retrieve the Google home page from the internet.
Another example is a picture of a cat on the internet. The URL for the image might be https://example.com/cat.jpg. When you type that URL into the address bar of your browser, the browser will retrieve the image of a cat from the internet.
In simple words, a URL is a reference to a web resource that specifies its location on a computer network and a mechanism for retrieving it.
Basic Structure of a URL
A URL (Uniform Resource Locator) is a web address that identifies a resource on the internet. It is composed of several parts, each of which serves a specific purpose.
The basic structure of a URL consists of the following parts:
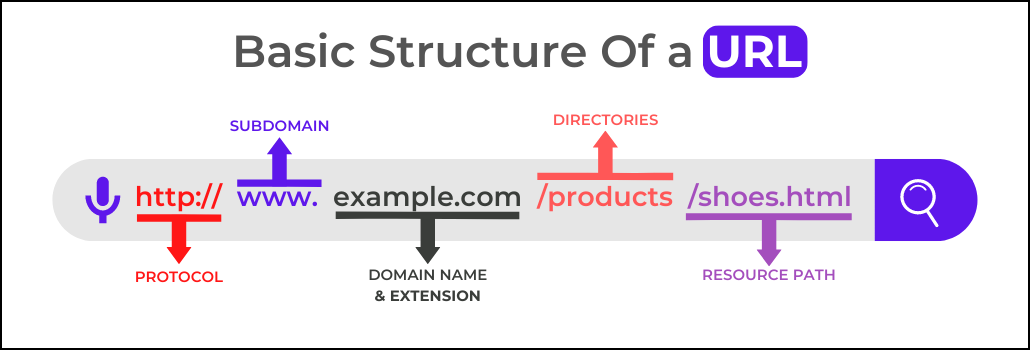
#1. Protocol
The Protocol is the first part of a URL that indicates how the web server should interpret the request. It is also known as the scheme and is usually followed by a colon and two forward slashes ://. The most common protocol used in URLs is the HyperText Transfer Protocol (HTTP). This is used to transmit webpages from server to browser. Other protocols can be used, such as Secure Socket Layer (SSL), File Transfer Protocol (FTP), and HyperText Transfer Protocol Secure (HTTPS).
Example:
HTTP://www.example.com
FTP://ftp.example.com
HTTPS://www.example.com
Learn more about the Difference Between HTTP & HTTPS.
#2. Subdomain (www)
A subdomain is a subsection of a larger domain. It is generally used to divide a website into different sections or areas, each with its own unique content. Subdomains appear directly to the left of the main domain e.g., store.example.com.
Subdomains are often used to create a separate website for a particular feature or product. For example, many large companies have a separate subdomain for their online store. The URL for the store might look something like this: store.example.com.
Subdomains can also be used to host different versions of a website in different languages. For example, a company may have a website for customers in the United States and another website for customers in Europe. The URLs for these websites might look like this: us.example.com and eu.example.com.
Subdomains are also used to create separate websites for different departments within a company. For example, a company may have a website for its marketing department and another website for its customer service department. The URLs for these websites might look like this: marketing.example.com and support.example.com.
Subdomains can also be used to provide access to a specific user group. For example, a company may provide its employees with access to a special website with additional resources. The URL for this website might look like this: employees.example.com.
Finally, many websites use subdomains for development and testing purposes. For example, a website may have a development subdomain where new features are tested before being added to the main website. The URL for this development subdomain might look like this: dev.example.com.
#3. Domain Name
A domain name is the part of a URL that identifies the website or web page a user wants to visit. It is the address of a website and serves as an identification label for a network of computers. For example, the domain name of the website TechABU is techabu.co.
When a user types a domain name into a web browser, the browser goes to a Domain Name System (DNS) server, which acts as a directory for all the domain names on the Internet. The DNS server looks up the domain name and translates it into an IP address, which is the numerical address of the web server where the website is located.
When registering a domain name, users have the option to purchase a domain name from a domain registrar or to create a domain name using a domain hosting service. Domain registrars are companies that allow users to register domain names for a fee. Domain hosting services provide users with a web hosting service and a domain name.
Domain names are an important part of any website or web page. It is the first element that a user will notice when they visit a website, so it is important to choose a domain name that accurately reflects the content and purpose of the website.
Read more about Domain Names.
#4. TLDs (Domain Extension)
TLD stands for “top-level domain,” which is the part of a web address located after the last dot. It is the extension that follows the last period in a web address. TLDs are the most recognizable parts of a URL, as they are typically three or four letters long and denote the type of website being accessed (e.g., .com, .org, .net, etc.).
TLDs are used to identify the purpose of a website and to categorize it. For example, a website ending in .com is typically a commercial site, while a website ending in .org is usually an organization or nonprofit. Government websites often end in .gov, while educational websites end in .edu. Other popular TLDs include .info and .net.
TLDs are also used to identify the country of origin for a website. For example, websites ending in .us are typically U.S.-based, while websites ending in .uk are generally from the United Kingdom. Other popular country-specific TLDs include .ca for Canada, .fr for France, .de for Germany, and .jp for Japan.
In addition to the standard TLDs, hundreds of other options are available. These are known as generic TLDs (gTLDs) and can be used for any purpose. Some popular gTLDs include .app, .guru, .club, and .blog.
TLDs are an integral part of URLs and offer users a quick way to determine the purpose and origin of a website.
#5. Resource Path
The resource path is the part of a URL that identifies the specific resource that is being requested. It is usually the path component of the URL and follows the domain name. The resource path is what web servers use to determine which page or file to serve up in response to a request.
For example, consider the URL http://www.example.com/products/shoes.html. The domain name is www.example.com, and the resource path is /products/shoes.html. In this case, the web server will serve the page located at /products/shoes.html in response to the request.
The resource path can also include query strings, which are used to provide additional information to the web server. For example, consider the URL http://www.example.com/products/shoes.html?color=blue&size=9. The resource path here is still /products/shoes.html, but the query string provides additional information to the web server. In this case, the web server can use this information to serve the appropriate page, such as a page with blue shoes in size 9.
The resource path is an important component of a URL. It is used by web servers to determine which page or file to serve in response to a request. It can also include query strings, which provide additional information to the web server.
#6. Parameters
Parameters are pieces of information that are passed in a URL to help refine the search request. Parameters are included in a URL after a question mark ? and are used to provide additional information to the server. They are typically used to specify the type of content to be displayed or the action to be performed.
Parameters in a URL consist of a name and a value, separated by an equals sign =. Multiple parameters can be used in a single URL, and each parameter must be separated by an ampersand (&).
For example, if you wanted to search for a specific item on Amazon, the URL might look something like this:
https://www.amazon.com/s?k=shoes&ref=nb_sb_nossThis URL contains two parameters:
k=shoes – This specifies the keyword (shoes) to search for
ref=nb_sb_noss – This specifies the type of results to be returned
In this example, the URL tells the server to search for the keyword “shoes” and to return results in a format known as nb_sb_noss.
A parameter is a value passed to an HTML page or a web application to customize the response for a particular client or user.
Common use cases of parameters include:
1. Filtering content: Parameters can be used to filter and display content based on certain criteria. For example, a web page may have a parameter that specifies a certain category or tag and then displays only content that matches that criteria.
2. Personalization: Parameters can be used to personalize content for a user. For example, a web application may have a parameter that specifies the user’s name, and then the content displayed is tailored for that user.
3. Pagination: Parameters can be used to control the pagination of content. For example, a web page may have a parameter that specifies the page number the user is viewing, and then the content displayed is only the content that matches that page number.
4. Searching: Parameters can be used in a search form to search for content. For example, a web page may have a parameter that specifies a keyword to search for, and then the content displayed is only the content that matches that keyword.
5. Redirection: Parameters can be used to redirect the user to a specific page within the web application. For example, a web page may have a parameter that specifies the page the user should be directed to, and then the browser will automatically redirect the user to that page.
Types Of URL
There are several different types of URLs, each with its own purpose and structure. Below are a few types of URLs:
1. Absolute URLs: Absolute URLs contain all the information that’s needed to access a page on the internet. They specify the protocol, domain name, and path of the page. For example, the absolute URL for Google’s homepage is https://www.google.com/.
2. Relative URLs: Relative URLs are used when the page being accessed is on the same domain as the page requesting the resource. They don’t include the protocol or domain name, just the path of the page. For example, the relative URL for Google’s homepage is: /.
3. Dynamic URLs: Dynamic URLs are used when a page contains content that changes based on user input or other criteria. They usually contain parameters that are appended to the URL string to indicate the type of content being requested. For example, a dynamic URL for a search query on Google might look like this: https://www.google.com/?q=search+query.
4. Short URLs: Short URLs are used to make long URLs more manageable. They’re typically redirected to longer URLs and are often used to make sharing links easier. For example, the short URL for Google’s homepage is shorturl.at/ayHOS.
5. Fragment URLs: Fragment URLs are used to navigate to a specific part of a page. They usually contain an anchor tag # followed by the ID of an element on the page. For example, the fragment URL for the contact form on Google’s homepage is https://www.google.com/#contact.
History Of URLs
The concept of URLs began in the early days of the Internet with the original Uniform Resource Identifier (URI) developed by Tim Berners-Lee in 1989. Berners-Lee’s goal was to create a standard way of identifying web pages and files so they could be easily located. He created the first URL syntax by combining the ideas of two existing technologies: the Domain Name System (DNS) and the Hypertext Transfer Protocol (HTTP).
In 1993, the formal definition of a URL was published in the Internet Engineering Task Force (IETF) RFC 1738. This document established the syntax for URLs, which is still in use today.
Since then, the URL has become a common way to locate resources on the Internet. URLs have been used to identify webpages, images, videos, and other types of files. URLs are used to access websites and other web-based services, such as email programs and social media platforms. They are also linked to specific parts of a website, such as a page or an image.
The URL is an integral part of the World Wide Web, and its use has grown significantly as the Internet has become more popular. URL usage has become so widespread that it is now one of the most common ways to locate information on the Internet.